Note
Go to the end to download the full example code.
Second-order IIR Filter with Architecture¶
from b_asic.architecture import Architecture, Memory, ProcessingElement
from b_asic.core_operations import Addition, ConstantMultiplication
from b_asic.schedule import Schedule
from b_asic.scheduler import ASAPScheduler
from b_asic.sfg import SFG
from b_asic.special_operations import Delay, Input, Output
in1 = Input("IN1")
c0 = ConstantMultiplication(5, in1, "C0")
add1 = Addition(c0, None, "ADD1")
T1 = Delay(add1, 0, "T1")
T2 = Delay(T1, 0, "T2")
b2 = ConstantMultiplication(0.2, T2, "B2")
b1 = ConstantMultiplication(0.3, T1, "B1")
add2 = Addition(b1, b2, "ADD2")
add1.input(1).connect(add2)
a1 = ConstantMultiplication(0.4, T1, "A1")
a2 = ConstantMultiplication(0.6, T2, "A2")
add3 = Addition(a1, a2, "ADD3")
a0 = ConstantMultiplication(0.7, add1, "A0")
add4 = Addition(a0, add3, "ADD4")
out1 = Output(add4, "OUT1")
sfg = SFG(inputs=[in1], outputs=[out1], name="Second-order direct form IIR filter")
The SFG is
sfg
Set latencies and execution times.
sfg.set_latency_of_type(ConstantMultiplication, 2)
sfg.set_latency_of_type(Addition, 1)
sfg.set_execution_time_of_type(ConstantMultiplication, 1)
sfg.set_execution_time_of_type(Addition, 1)
Create schedule.
schedule = Schedule(sfg, scheduler=ASAPScheduler(), cyclic=True)
schedule

Reschedule to only require one adder and one multiplier.
schedule.move_operation('add3', 2)
schedule.move_operation('cmul4', -4)
schedule.move_operation('cmul3', -5)
schedule.move_operation('cmul5', -2)
schedule.move_operation('cmul2', 1)
schedule

Extract operations and create processing elements.
operations = schedule.get_operations()
adders = operations.get_by_type_name('add')
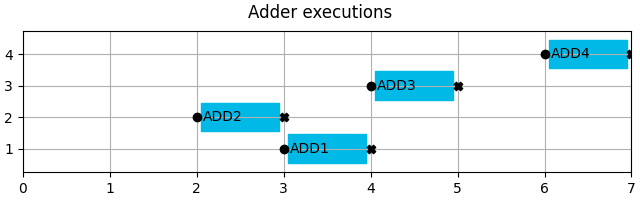
adders.show(title="Adder executions")
mults = operations.get_by_type_name('cmul')
mults.show(title="Multiplier executions")
inputs = operations.get_by_type_name('in')
inputs.show(title="Input executions")
outputs = operations.get_by_type_name('out')
outputs.show(title="Output executions")
adder = ProcessingElement(adders, entity_name="adder")
multiplier = ProcessingElement(mults, entity_name="multiplier")
pe_in = ProcessingElement(inputs, entity_name='input')
pe_out = ProcessingElement(outputs, entity_name='output')

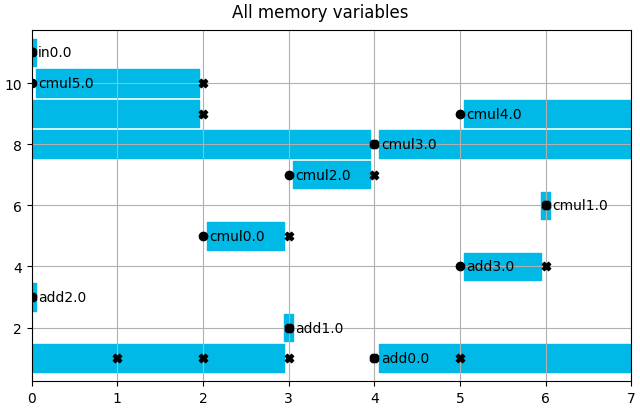

Extract and assign memory variables.
mem_vars = schedule.get_memory_variables()
mem_vars.show(title="All memory variables")
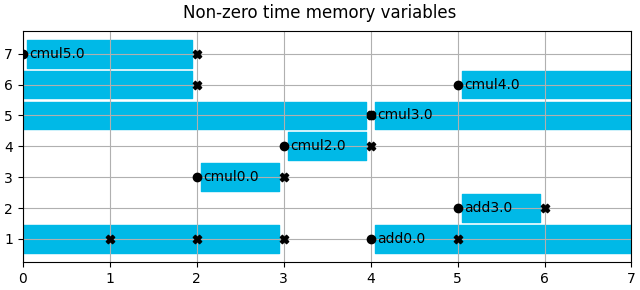
direct, mem_vars = mem_vars.split_on_length()
mem_vars.show(title="Non-zero time memory variables")
mem_vars_set = mem_vars.split_on_ports(read_ports=1, write_ports=1, total_ports=2)
memories = []
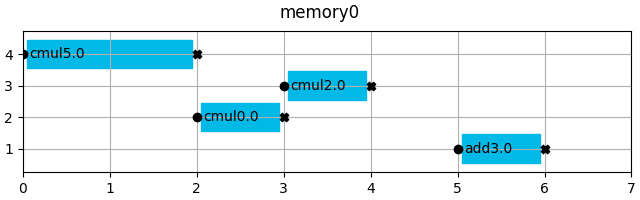
for i, mem in enumerate(mem_vars_set):
memory = Memory(mem, memory_type="RAM", entity_name=f"memory{i}")
memories.append(memory)
mem.show(title=f"{memory.entity_name}")
memory.assign("left_edge")
memory.show_content(title=f"Assigned {memory.entity_name}")
direct.show(title="Direct interconnects")
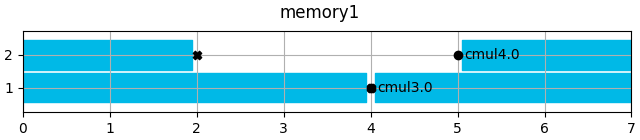
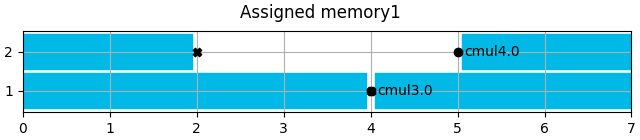







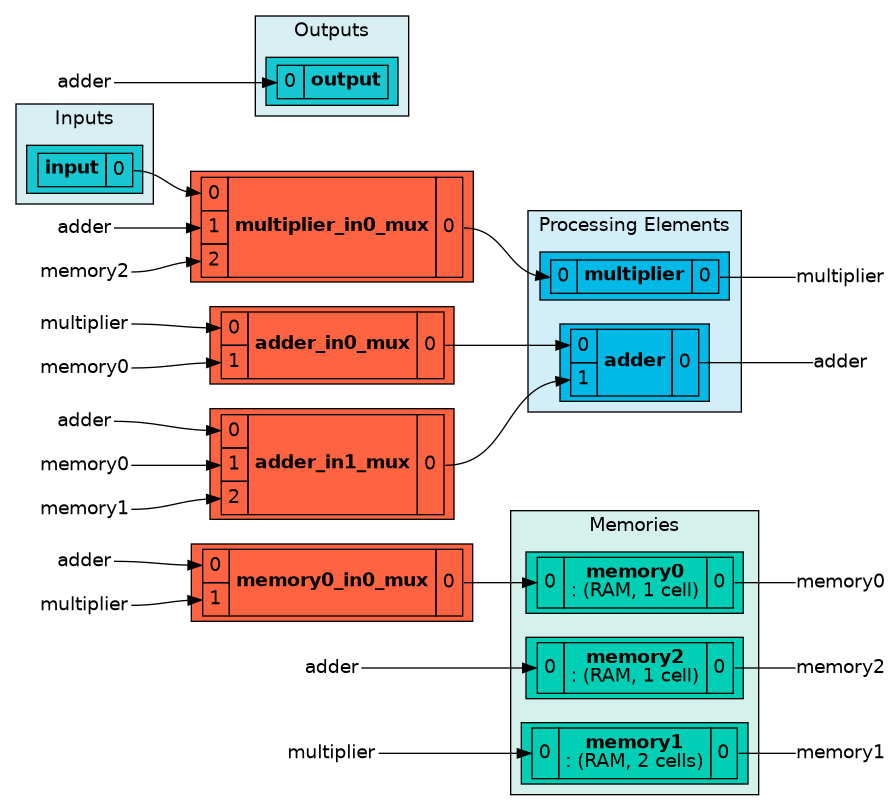
Create architecture.
arch = Architecture(
{adder, multiplier, pe_in, pe_out}, memories, direct_interconnects=direct
)
The architecture can be rendered in enriched shells.
arch
Total running time of the script: (0 minutes 1.872 seconds)